FoodMenu-NER-pt-br is a Named Entity Recognition (NER) model specialized for Brazilian Portuguese (pt-br) texts, designed to extract ingredients and their quantities from food-related content such as menus and recipes.
- Base Model:
pt_core_news_lg(spaCy) - Pipeline: Preserves all components except "ner", "trf_wordpiecer" and "trf_tok2vec"
- Fine-tuning: Transfer Learning focused on NER layer
- Number of Iterations: 60
- Batch Size: Dynamic (4 to 16, using compounding)
- Dropout Rate: 0.3
QUANTIDADE: Identification of measurements and quantitiesINGREDIENTE: Recognition of food ingredients
FoodMenu-NER-pt-br/
├── data/
│ └── dataset.json
├── model/
│ └── food_item_ner_pt/
├── src/
│ ├── utils.py
│ ├── evaluate_model.py
│ ├── inference.py
│ └── train.py
├── .gitignore
├── requirements.txt
└── README.md
- Total Examples: 243
- Data Split: 80% training, 20% validation
- Entity Distribution:
QUANTIDADE: 301 instancesINGREDIENTE: 1130 instances
{
"text": "500g de macarrão com molho",
"entities": [
{
"start": 0,
"end": 4,
"label": "QUANTIDADE",
"text": "500g"
},
{
"start": 8,
"end": 16,
"label": "INGREDIENTE",
"text": "macarrão"
}
]
}To train the model, run:
python src/train.pyTo evaluate the trained model:
python src/evaluate_model.py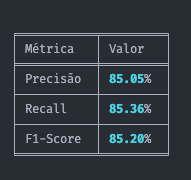
import spacy
nlp = spacy.load("model/food_item_ner_pt")
text = "250g de filé de frango grelhado, temperado com limão, azeite e ervas finas. Servido com arroz basmati e legumes assados como abóbora e cenoura"
doc = nlp(text)
for ent in doc.ents:
print(f"{ent.label_}: {ent.text}")You can also run predictions using the command line:
python src/inference.py --text "250g de filé de frango grelhado, temperado com limão, azeite e ervas finas. Servido com arroz basmati e legumes assados como abóbora e cenoura"Available Arguments:
| Argument | Type | Required | Default | Description |
|---|---|---|---|---|
--text |
string | Yes | - | Input text for entity recognition |
--model |
string | No | model/food_item_ner_pt |
Path to the trained model directory |
--display |
string | No | cli |
Output format: cli for terminal or html for browser |
Examples:
Basic usage with CLI output:
python src/inference.py --text "500g de açúcar e 2 ovos"Using a custom model path:
python src/inference.py --text "300ml de leite" --model "path/to/custom/model"HTML visualization in browser:
python src/inference.py --text "1kg de farinha de trigo" --display htmlComplex recipe analysis:
python src/inference.py --text "Para o bolo: 3 ovos, 200g de açúcar, 250ml de leite e 300g de farinha. Para a cobertura: 100g de chocolate e 50ml de creme de leite."Inference Output:

- Model optimized only for culinary texts
- May struggle with regional culinary slang
- Performance not tested on very long texts
This project is released under the MIT License - refer to the LICENSE file for details.