MovieLens data can be used in recommendation system research. It has millions of real-world ratings.
Movie ratings are made on a 5-star scale, with half-star increments (0.5 stars - 5.0 stars).
In this project, we will find out good preprocessing steps and models using evaluation metrics such as HR@10, NDCG@10, and RMSE. Until now, research has been progressed only on RMSE metric.
I organized related work in "MovieLens Paper" folder and "Recommender-System-Study" folder.
The results of studies conducted using MovieLens dataset can be seen in the "MovieLens Paper" folder.
You can learn basic concepts of the recommendation system using "Recommender-System-Study" folder.
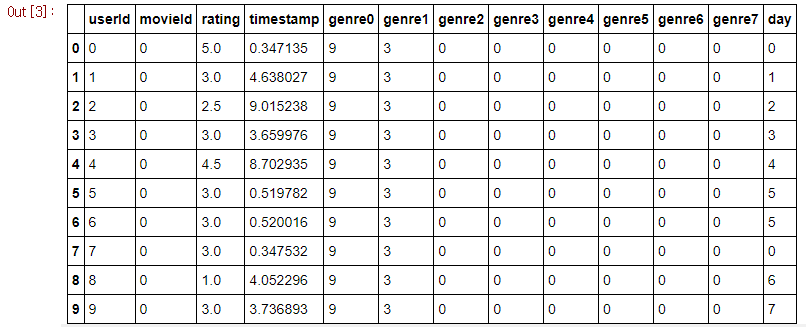
- Added a "timestamp" value of when does the user watched the movie since the movie was released.
- Genre forms such as "Romance, Adventure" was changed to numerical values.
- The "timestamp" value was grouped at intervals by two weeks and defined as "day" value.
- The train and test datasets are separated at a ratio of 9:1.
- Movie ratings are made on a 5-star scale (0.5 stars - 5.0 stars). We can think that prediction can be (sigmoid output) * 4.5 + 0.5 because it will range between 0.5 and 5. However, using (sigmoid output) * 5.5 gives me much better accuracy in the movie rating prediction. It is better to have a small extra prediction range.
- L2 regularization helps prevent overfitting. Experimentally, the L2 regularization cost has to be between 2% to 4% of the total cost.
- The Wide & Deep model that uses both Matrix Factorization and MLP layers showed good performance.
- Mixture-Rank Matrix Approximation(MRMA) has various embedding sizes and combines each matrix factorization model. The larger model has the higher performance, but there is also a trade-off that increases total time complexity.
- Batch Normalization and Dropout techniques showed poor results in both train and test datasets.
- Adam optimizer performs better than any other optimization algorithm.
- It is better to put metadata of items such as genres in the MLP input layer without putting them in matrix factorization.
To see more details about my model refer to
https://github.com/itemgiver/MovieLens/blob/main/src/MovieLens10M_RMSE_7672.ipynb
Test RMSE = 0.7672
You can see the other results on the RMSE value in this link.
https://paperswithcode.com/sota/collaborative-filtering-on-movielens-10m?metric=RMSE
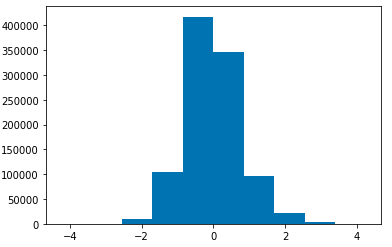
Difference between the actual value and the predicted value Histogram