Разработка системы с web-интерфейсом для сопоставления характеристик товаров маркетплейса с их эталонными значениями
Команда: i plow()
Кейс решён в рамках хакатона AgoraHack2022
Дана база товаров со следующими полями.
| Поле | Инфо |
|---|---|
name |
Наименование товара |
is_reference |
True, если товар является эталоном. Тогда reference_id "None". |
product_id |
id продукта |
reference_id |
id эталона для этого продукта |
props |
массив строк-свойств товара |
В ней имеются как товары-эталоны (471 шт.), так и товары продавцов (2780 шт.)
Основываясь на этих данных необходимо разработать микросервис, сопостовляющий товары продавцов с эталонами. Взаимодействие с сервисом должно осуществляться посредством отправки POST запроса с JSON-массивом, содержащим товары. Ответ сервиса должен состоять из id эталонов для каждого товара.
- Задача
- Алгоритм
- Ход решения
- Дополнительные фичи
- Наш Стек
- Архитектура микросервиса
- Как запустить?
- i plow()
Для матчинга поступающего на вход сервису товара мы выполняем следующие действия:
- Конкатенируем название и все свойства товара.
- Отдаем эту строчку в MongoDB - перед поиском он автоматически производит лемматизацию.
- Затем производится полнотекстовый поиск по этой строке по имеющимся эталонам, у которых так же предварительно сконкатенированны название и свойства.
- После мы выбираем эталон с наибольшим textScore и возвращаем его id.
Для оценки результатов работы нашего алгоритма в качестве метрики мы выбрали Accuracy.
Accuracy = Количество верно предсказанных эталоннов / Количество предсказаний
Тесты проводились на устройстве с 8 ГБ оперативной памяти и процессором AMD FX(tm)-4350 Quad-Core Processor, информацию о котором вы можете видеть ниже.
$ cpufetch
Name: AMD FX(tm)-4350 Quad-Core Processor
Microarchitecture: Piledriver
Technology: 32nm
Max Frequency: 4.200 GHz
Cores: 2 cores (4 threads)
AVX: AVX
FMA: FMA3,FMA4
L1i Size: 64KB (128KB Total)
L1d Size: 16KB (64KB Total)
L2 Size: 2MB (4MB Total)
L3 Size: 8MB
Peak Performance: 134.40 GFLOP/sСперва мы просто произвели поиск MongoDB по названию. Производительность нашего решения мы оценивали, подавая на вход алгоритму батчи разных размеров (при этом матчинг производился относительно всех предоставленных эталонов). Результаты первого подхода можно увидеть ниже.
| Размер батча | Время обработки батча (с) | Скорость матчинга (Матчей/сек) | Accuracy |
|---|---|---|---|
| 100 | 0.2715 | ~ 368 | 0.8800 |
| 1000 | 1.6553 | ~ 604 | 0.8840 |
| 2780 | 4.7229 | ~ 589 | 0.8996 |
| ------------ | ---------------- | ---------------------------- | -------- |
| Итог | - | ~ 520 | 0.8996 |
Мы получили недурное качество, но мы видели еще горизонты для улучшения наших результатов.
- Мы использовали свойства товаров при поиске (props)
Придумали конкатенировать их с названием товара и искать по ним обоим. В итоге это значительно повлияло на скорость предсказания, зато мы добились повышения точности на 0.04, по сравнению с прошлым вариантом, что является значительным приростом и увеличло точность нашей модели до ~0.935. результаты бенчмарков можно видеть ниже.
| Размер батча | Время обработки батча (с) | Скорость матчинга (Матчей/сек) | Accuracy |
|---|---|---|---|
| 100 | 0.5504 | ~ 181 | 0.9500 |
| 1000 | 5.5677 | ~ 179 | 0.9260 |
| 2780 | 16.7053 | ~ 166 | 0.9309 |
| ------------ | ---------------- | ---------------------------- | -------- |
| Итог | - | ~ 175 | 0.9309 |
Как можно заметить, время обработки батчей увеличилось практически вдвое, а то и втрое (оно и ясно, текста стало в два три раза больше на каждый товар), вдобавок это с лихвой окупилось повышением точности. По ТЗ скорость матчинга должна быть не менее 100 товаров в секунду, и в этот интервал мы все ещё укладываемся.
- (Неудачно) Разделили и добавили по частям именования со спецсимволами. (Было "сплит-система", стало "сплит-система сплит система")
При таком подходе точность модели снизилась где-то на 8-12 процентов, поэтому мы отказались от этой затеи. Предположительно эта идея не сработала, поскольку она уменьшала связи между словами и общее количество уникальных слов, путала поиск и тем самым ухудшала нахождение правильного эталона.
- Очистили данные от специальных символов
Такое действие позволяет нам уменьшить общее количество токенов, уменьшить количество текста, по которому выполняется поиск. Использование этого подхода увеличило точность нашей модели на 0.02 и слегка (на 12%) увелилась скорость по сравнению с предыдущим успешным вариантом. Данные по бенчмарчку можно увидеть ниже.
| Размер батча | Время обработки батча (с) | Скорость матчинга (Матчей/сек) | Accuracy |
|---|---|---|---|
| 100 | 0.5171 | ~ 194 | 0.9800 |
| 1000 | 5.0261 | ~ 199 | 0.9340 |
| 2780 | 14.2704 | ~ 195 | 0.9503 |
| ------------ | ---------------- | ---------------------------- | -------- |
| Итог | - | ~ 196 | 0.9503 |
Чтобы у вас была возможность протестировать производительность и убедиться в легитимности тестов, мы рассказываем, как вы можете запустить наш тест на своей машине в секции Как тестировали наше решение мы
- Система пользовательских прав - Набор методов для интеграции системы пользовательских прав.
- Оперирование данными - Набор методов для добавления новых эталонов.
- Простота использования - Интерактивная документация, предоставляемая FastApi, позволяет "пощупать" API с помощью web-интерфейса.
- Простота интеграции - Контейнеризация микросервиса с помощью Docker, позволяющая без лишних усилий интегрировать его в рабочий процесс.
- Безграничная масштабируемость - нет необходимости переобучать модель при добавлении новых эталонов.
- Высокая производительность - высокая скорость работы алгоритма позволяет использовать этот микросервис в HighLoad проектах.
- Python - основной язык
- FastApi - Rest/API
- pymystem3 - лемматизация эталонов
- MongoDB - хранение и поиск по эталонам
- PostgreSQL - хранение информации о пользователях
- Docker, docker-compose - контейнеризация
- uvicorn - асинхронный фреймворк для веб-сервера

Для запуска решения требуется наличие в системе следующих утилит:
Pythonверсии3.10и вышеDockerdocker-composeверсии2.6и вышеMake
- При необходимости вы можете отредактировать файл конфига
.envпод свои нужды, со следующим содержимым:
POSTGRES_USERNAME=...
POSTGRES_PASSWORD=...
POSTGRES_DATABASE=...
POSTGRES_HOST=...
MONGO_USER=...
MONGO_PASSWORD=...
MONGO_DATABASE=...
MONGO_HOST=...
FASTAPI_PORT=...
FASTAPI_SECRET=...
FASTAPI_HASH_ALGORITHM=...
FASTAPI_HASH_EXPIRATION=...- Запуск баз данных:
make dbmake runПосле этого ваш сервис станет доступен на localhost:8100, если вы не меняли порт в .env, а на localhost:8100/docs будет располагаться интерактивная документация по API.
Чтобы выключить все контейнеры (в т.ч. и базы данных), пропишите make down.
- Создание виртуальной среды и установка зависимостей:
make prepare- Запуск сервиса:
make run-localДля тестирования сервиса удобно использовать curl:
$ curl -X 'POST' \
'http://0.0.0.0:8100/match_products' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '[
{
"id": "0039af5efceac4ab",
"name": "Холодильник Бирюса 118",
"props": [
"Мощность замораживания 4 кг/сутки"
]
},
{
"id": "004f2158acb8165c",
"name": "ASUS TUF-GTX1660S-O6G-GAMING Видеокарта",
"props": [
"Объем видеопамяти\t6144 МБ",
"Частота памяти\t14002 МГц",
"Разъемы и интерфейсы выход DVI, выход DisplayPort, выход HDMI"
]
}
]'
[{"id":"0039af5efceac4ab","reference_id":"28085e941cde1639"},{"id":"004f2158acb8165c","reference_id":"9afe55bb4bf1e8a8"}]- Запустите сервис согласно инструкции по запуску
$ make db && make run-
Откройте web-интерфейс,
localhost:8100/docs -
Найдите метод
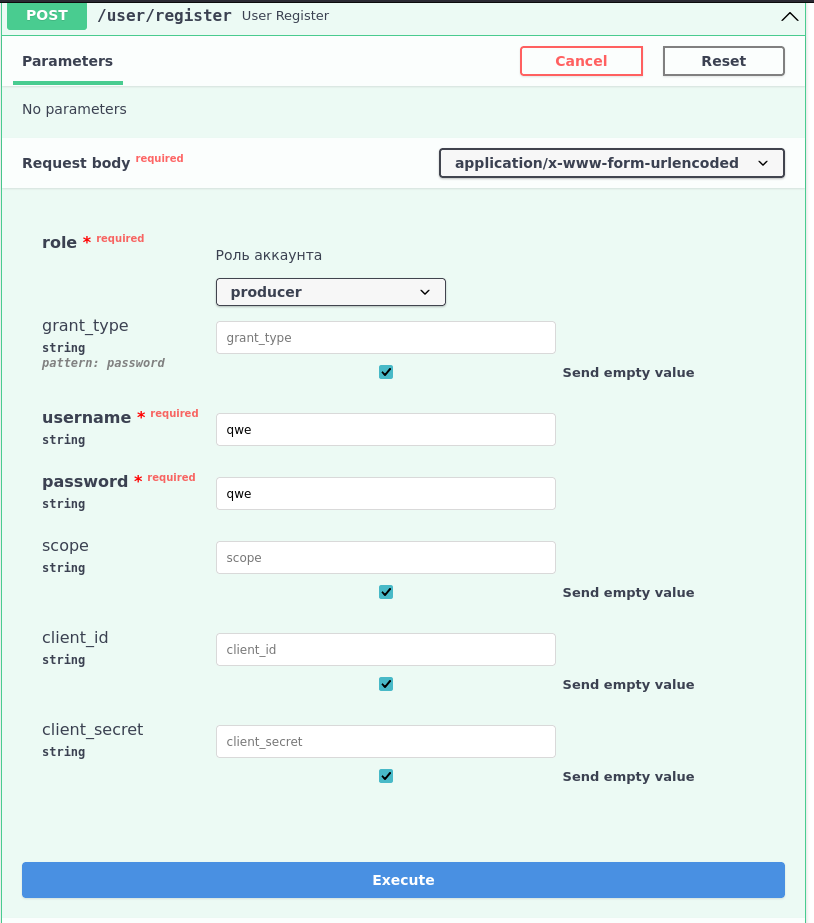
/user/register, нажмите на него, затем нажмите на"Try it out"и зарегистрируйте пользователя-продюсера. Чтобы это сделать, введите username и password, и нажмите execute.
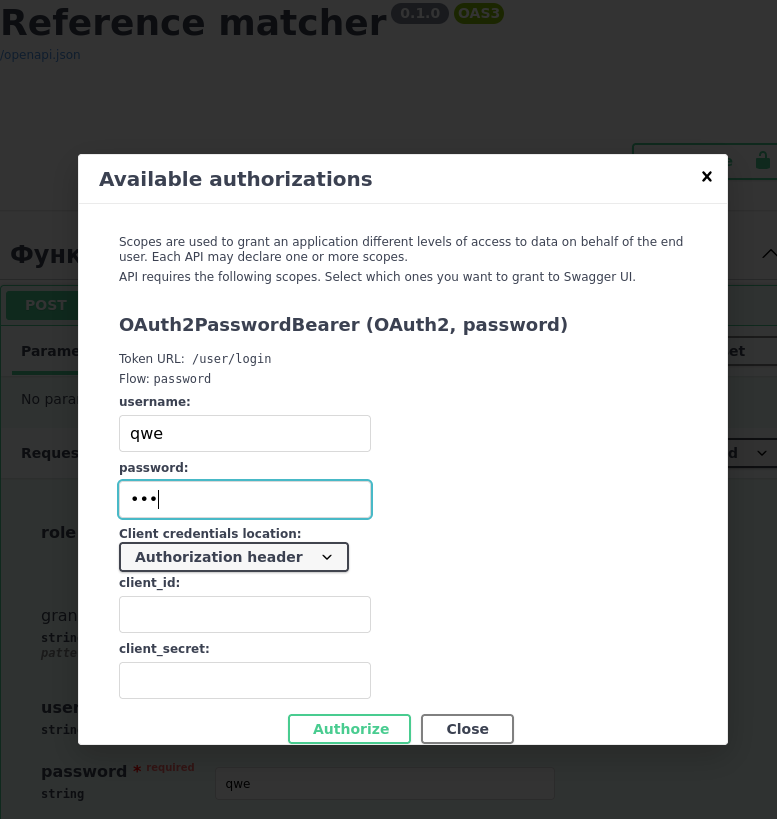
- Авторизируйтесь в web-интерфейсе: для этого нажмите
Authorizeв правом верхнем углу и введите username и password от аккаунта продюсера.
-
Загрузите тестовые данные. В качестве тестовых данных мы использовали товары, которые не являются эталонами из предоставленного датасета ( файл
tests/test_products.json). Чтобы загрузить данные, найдите метод/producer/upload/file, нажмите на него, нажмите на"Try it out"и загрузите json-файл с тестовыми данными. Нажмите execute. -
Запустите тест!
(.venv) [huscker@arch backend2]$ make test
docker exec -it api python -m tests.accuracy
{'good': 2630, 'total': 2780, 'skips': 0, 'accuracy': 0.9460431654676259}
11.498264879999624 seconds
==================================================Обратитесь к нам! Мы будем рады вам помочь и ответить на все ваши вопросы.
- Голубев Егор - бекенд-разработчик
- Тампио Илья - ML-специалист
- Лернер Роман - Product менеджер
- Молоткова Ника - UI/UX дизайнер
- Лебедева Татьяна - Frontend-разработчик